How to Scrape Data from a Website with Website Scraper and E-Mail Extractor
How to Scrape Data from a Website with Website Scraper and E-Mail Extractor
As well as being able to scrape and extract data from the search engines, Google Maps, Business directories and social media, the website scraper can also extract data from your website list. Likewise, you can use the website scraper to extract and scrape extra and missing data for your results from scraping data. We will show you the steps for extracting data 1) from website lists and 2) scraping and extracting missing data in your Excel CSV results file. We are going to begin this tutorial on website scraping with the basic software configurations.
Proxy Settings
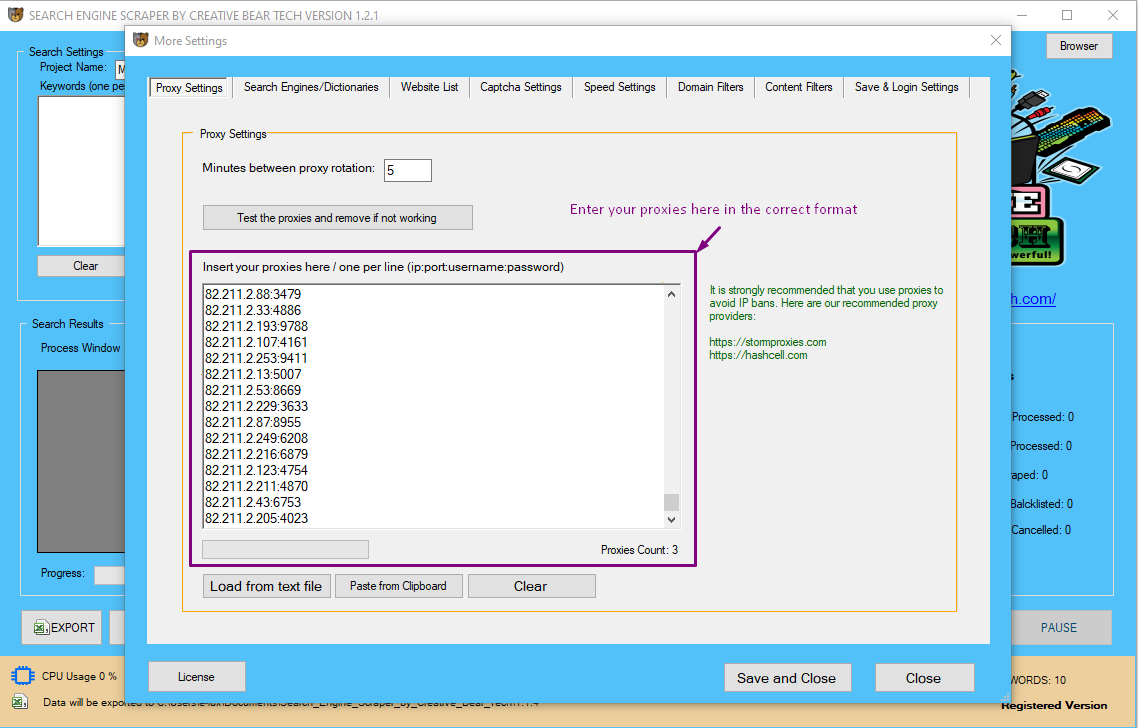
If you are going to extract data from your website list or your CSV file with results from scraping, then you do not need proxies. Proxies are needed for scraping data from the search engines, Google Maps and Business Directories. The majority of websites will not need proxies. However, if you like, you can still use proxies but these are not needed at this stage.
You will need to add your proxies in the following format:
IP:PORT:USERNAME:PASSWORD
IP:PORT
We recommend private and shared proxies as these are the most stable. Backconnect rotating proxies are good for intense scraping as they give a large pool of proxies and each proxy changes at regular intervals of time/at every http request. We do not generally recommend public proxies as they tend to be unstable. Once you have added your proxies to the proxies pane, click on "test the proxies and remove if not working". The proxy tester will remove all non-working proxies. You should then set the delay between proxy rotation.
Search Engines/Dictionaries
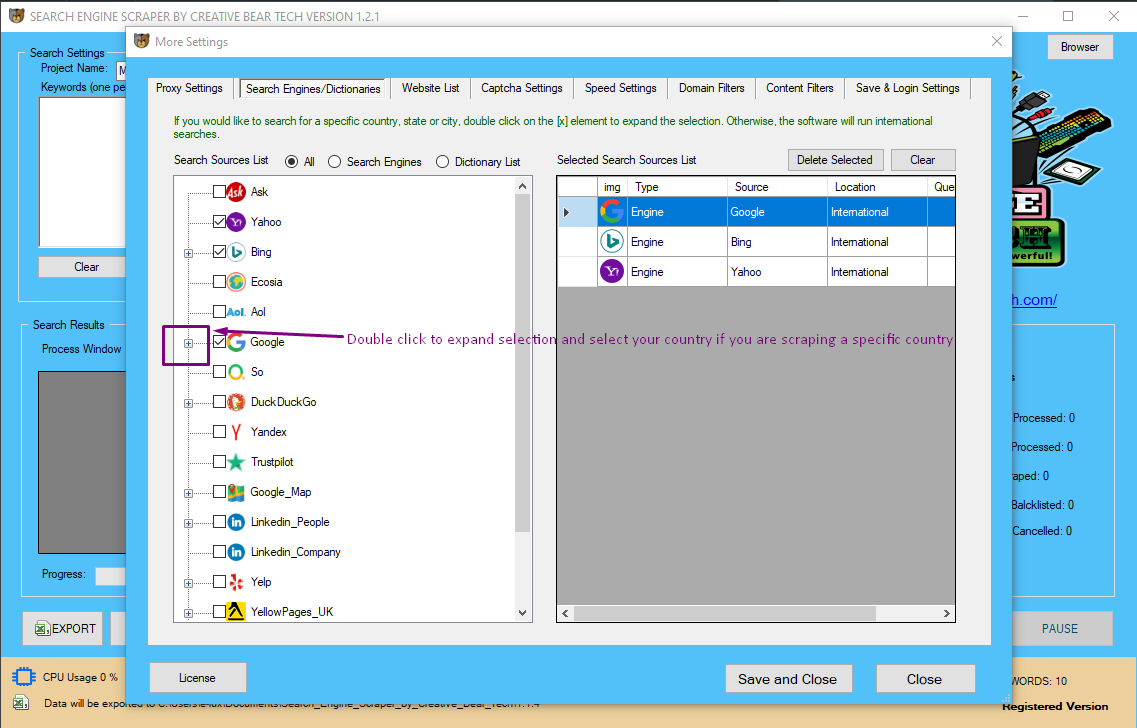
You do not need to select any of these as you are going to be extracting business contact data either from your website list or your CSV results file to fill in the missing data. This section will not apply so you can skip it.
Website List
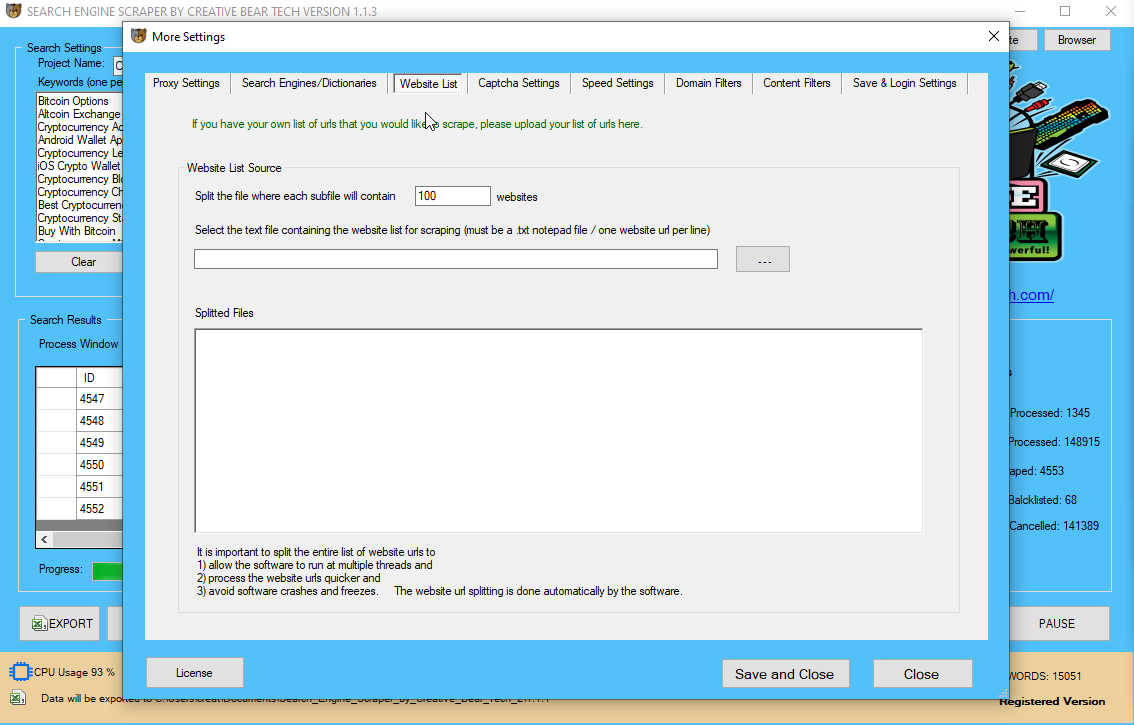
This is the most important section for current purposes. Here, you will need to upload either your text notepad file with urls (one url per line) or your Excel CSV results file. If you are going to upload your website list, the website scraper is going to go to each site and feth all the data including business name, email, address, website, telephone number, social media links etc. If you have already scraped your data using our search engine scraper but would like to scrape/extract any missing data such as addresses, telephone numbers, etc.
IMPORTANT: IF YOU ARE GOING TO BE UPLOADING A CSV FILE, MAKE SURE IT IS NOT YOUR RESULTS FILE AS IT IS FORMATTED DIFFERENTLY AND MAKE SURE THAT THE CSV HAS ALL THE FIELDS IN THE CORRECT FORMAT. WE RECOMMEND JUST COPYING THE LATEST CSV FILE FROM YOUR PROJECT FOLDER. FOR EXAMPLE, IN OUR PROJECT FOLDER "Food_and_Beverage_Industry_Database", WE HAVE THE FOLLOWING FILES
Food_and_Beverage_Industry_Database_14-04-2020 (csv scraping file)
Food_and_Beverage_Industry_DataResults__21-03-2020 (results file)
Food_and_Beverage_Industry_Emails__21-03-2020 (just emails)
We need to upload the first file: "Food_and_Beverage_Industry_Database_14-04-2020" as the columns are formatted correctly here.
DO NOT upload the file with "dataresults", it is formatted differently.
If you are uploading a notepad text file, the software will split the file into files comprised of X number of websites. This feature is helpful in splitting larger website lists as it makes it easier to run the website scraper on multiple threads and each thread would process one file at a time. It is easier for the individual scraper to process smaller website lists than larger ones.
Captcha Settings
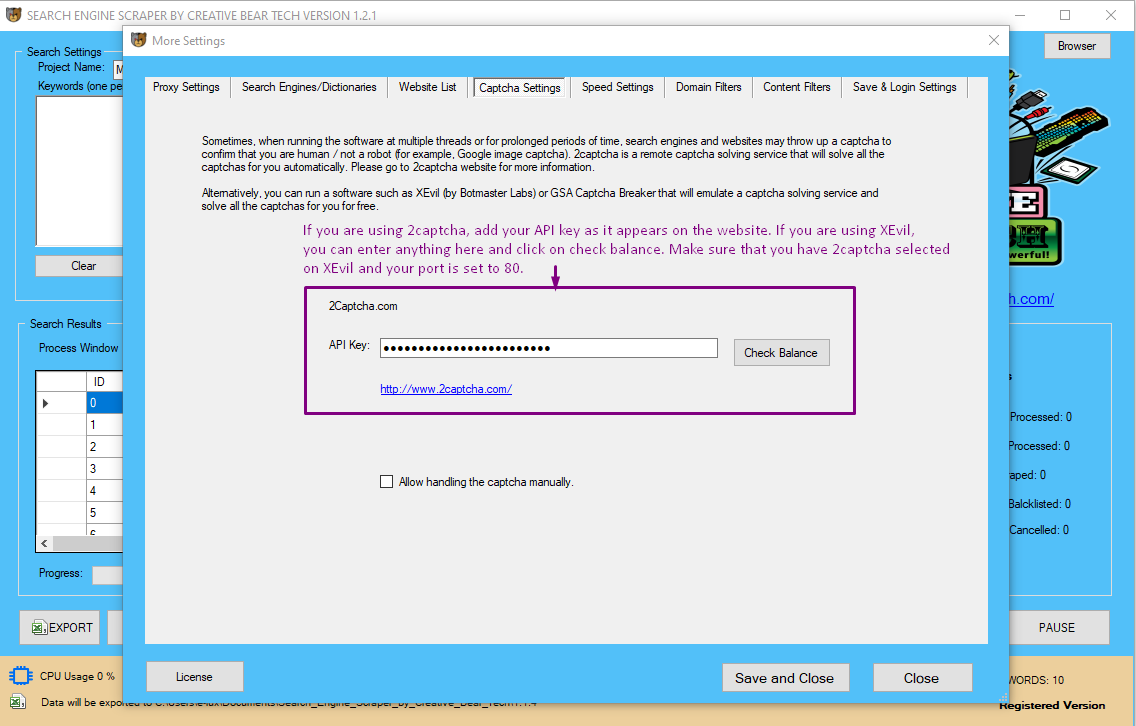
Captcha settings contain a remote captcha solving software API for 2captcha. Remote captcha solving has the objective of automatically solving all types of captchas including Google image recaptcha to confirm that you are human/not a robot. Generally, captcha solving is required when scraping the search engines, Google Maps and business directories. Scraping website list will require captcha solving less often. Nevertheless, sites such as Facebook and Twitter may sometimes require you to confirm that you are not a human by solving an image captcha. It is therefore advisable to use an external captcha solving service. As well as using 2captcha, you can also use XEvil, which is a desktop captcha-solving software that will solve captcha for free. Please read our separate guide on how to connect XEvil with our website scraper and emailextractor.
Speed Settings
The speed settings will control the speed of the website data scraper. You do not need to select anything for the total number of search results (websites) to parse per keywords because you are not going to be scraping the search engines.
You will need to select the maximum number of emails to extract from the same website. To save on memory and CPU, disable images in the web browser. You can enable application activity log and individual threads activity log in order to collect data so that in case something goes wrong, we can trace the problem through the logs. These options will take up more processing power. The gold standard is to have the application activity log enabled and individual thread activity log disabled.
Next, we recommend that you scrape Facebook and Twitter for extra data: these social media sites are important for quality data.
Domain Settings

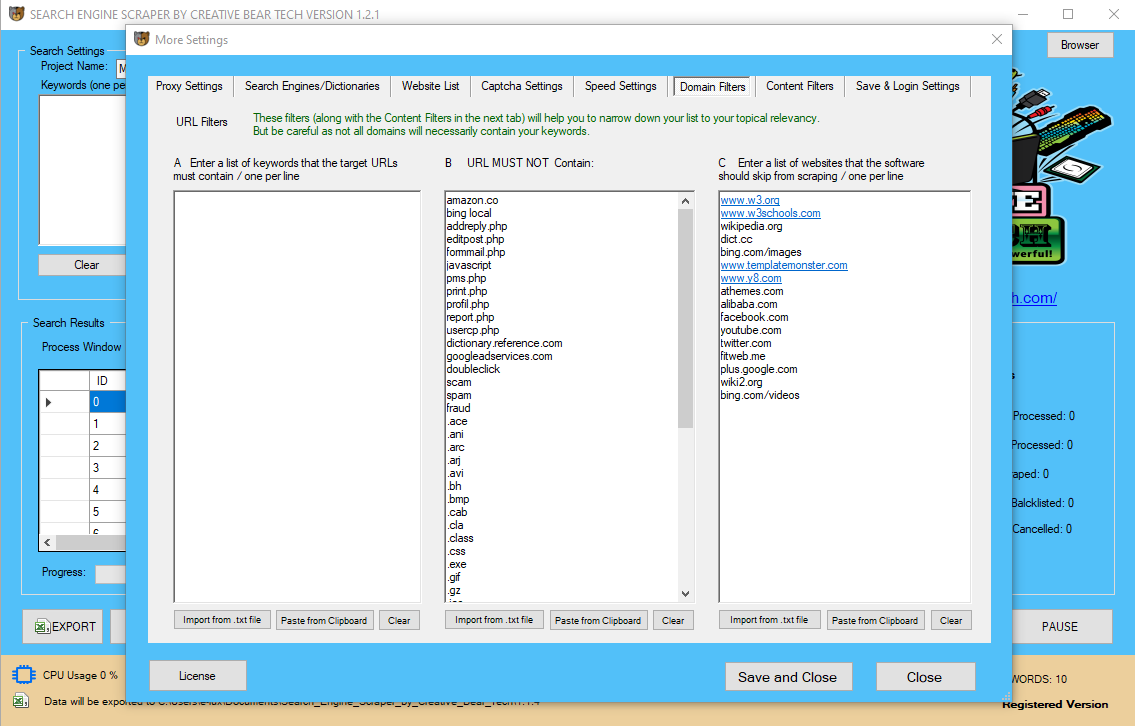
Here, you can enter the keywords that your websites must and must not contain. This domain-level will skip the urls that do not contain a certain keyword. Please note that this filter is best suited for business niches that have a prevailing keyword. For example, if we take the cbd niche, most urls will contain the keyword "CBD". However, a lot of websites will be branded and may not contain the keyword in the website url. Use this filter with caution as it can reduce the number of results.
Content Filters
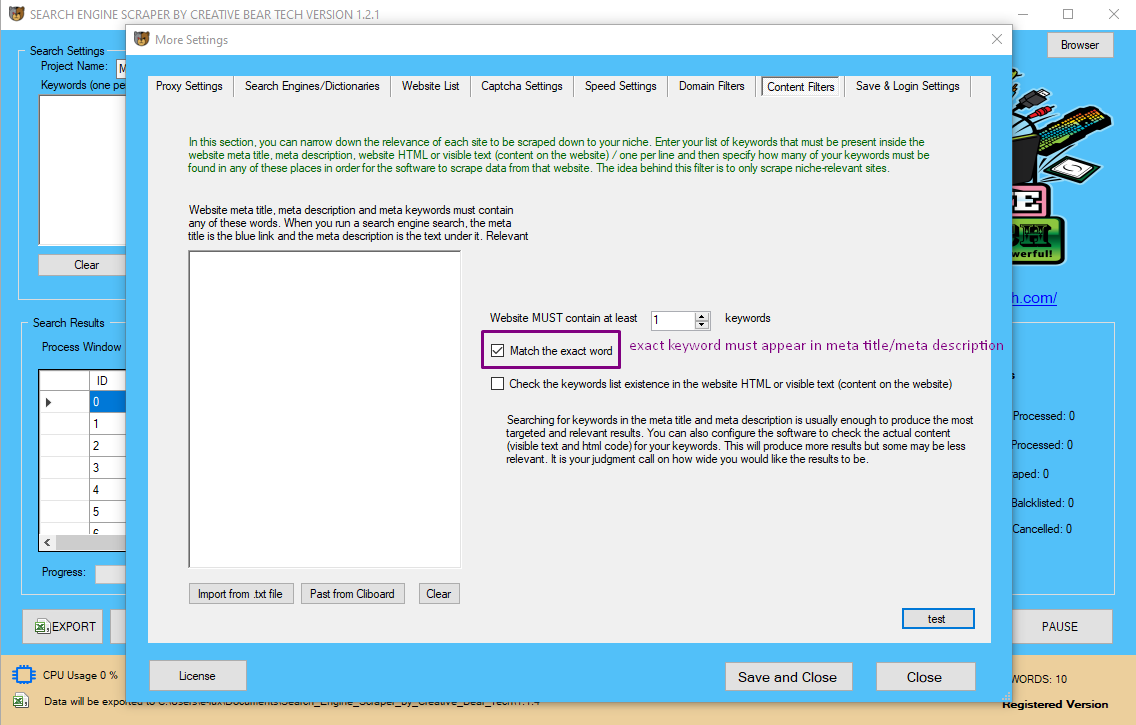
Here, you can enter a set of keywords that must be present in a website's meta title or meta description. Most relevant websites will contain your set of keywords. For example, almost all CBD/Hemp related websites will contain the keywords CBD or Hemp because this is waht the product is "CBD". The same applies to the vaping industry, although here there will be more keyword variations such as vape, vaping, vaper, vapor, vaporizer, ecigarette, e-cigarette, e-liquid, eliquid, e-liquids, eliquids, ejuice, ejuices, e-juice, e-juices, etc. Other business niches such as beauty products, sports nutrition, food and beverage will contain a very wide range of keywords that it is very difficult to quantify them and put them in the list. Generally, if you want to apply content filters to such categories, go for the category keywords that for the niche. You can get these from sites such as Amazon, eBay, etc.
Check the "exact match" option if you would like for the website scraper to only extract data from websites that contain the exact content keywords. You can also check the box to check for keywords in website body text/html. However, this is going to produce very broad results. As you can appreciate, even the most irrelevant websites may contain your keywords. However, if you are looking for something specific such as a brand name (i.e. sites on which a brand is mentioned) then this would be an appropriate option.
Save & Login Settings
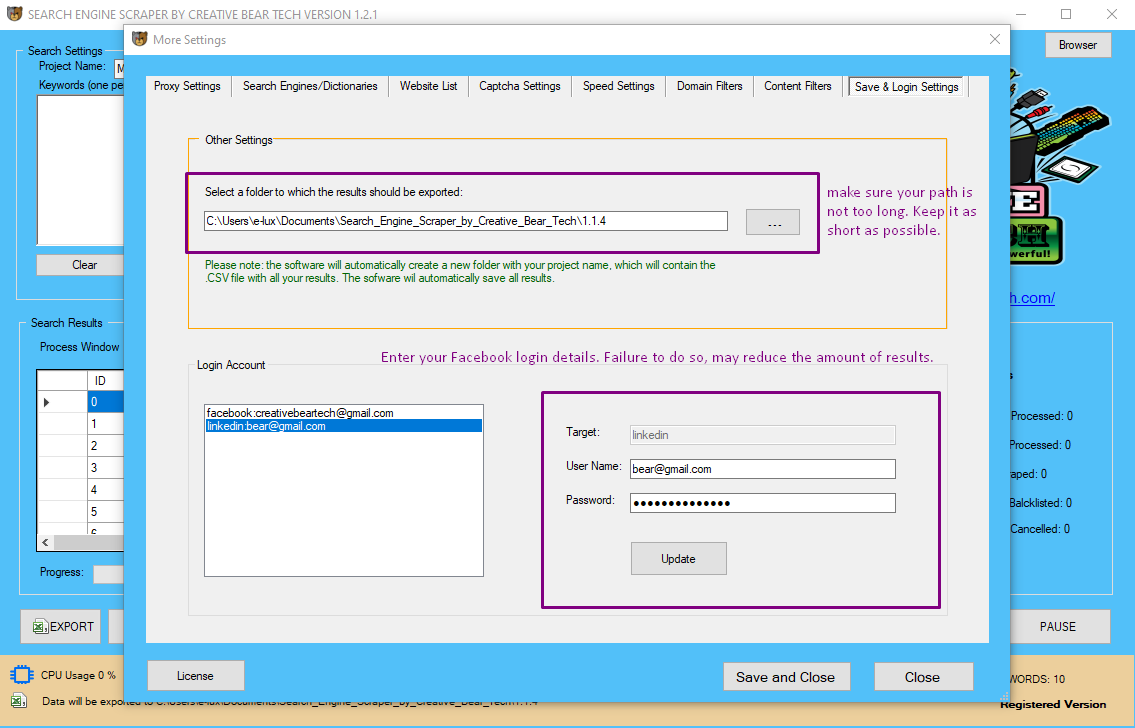
Here, you need to specify a path to which your project and results will be saved. We recommend to keep this folder path as short as possible: ideally, two to three levels.
Next, you will need to enter your Facebook and LinkedIn login details. This is especially important because sometimes, Facebook will require you to login in order to view a Facebook business page. Therefore, if you are not logged in, the website scraper will get extract less results and as the scraper is using Facebook to retrieve extra business leads, it is important that you are logged in. We recommend creating a separate Facebook account just for scraping on your desktop/using your local IP. The website scraper is going to access Facebook on a single thread with greater delays in order to emulate real human behaviour and avoid Facebook account bans.
Website Scraper - Main GUI
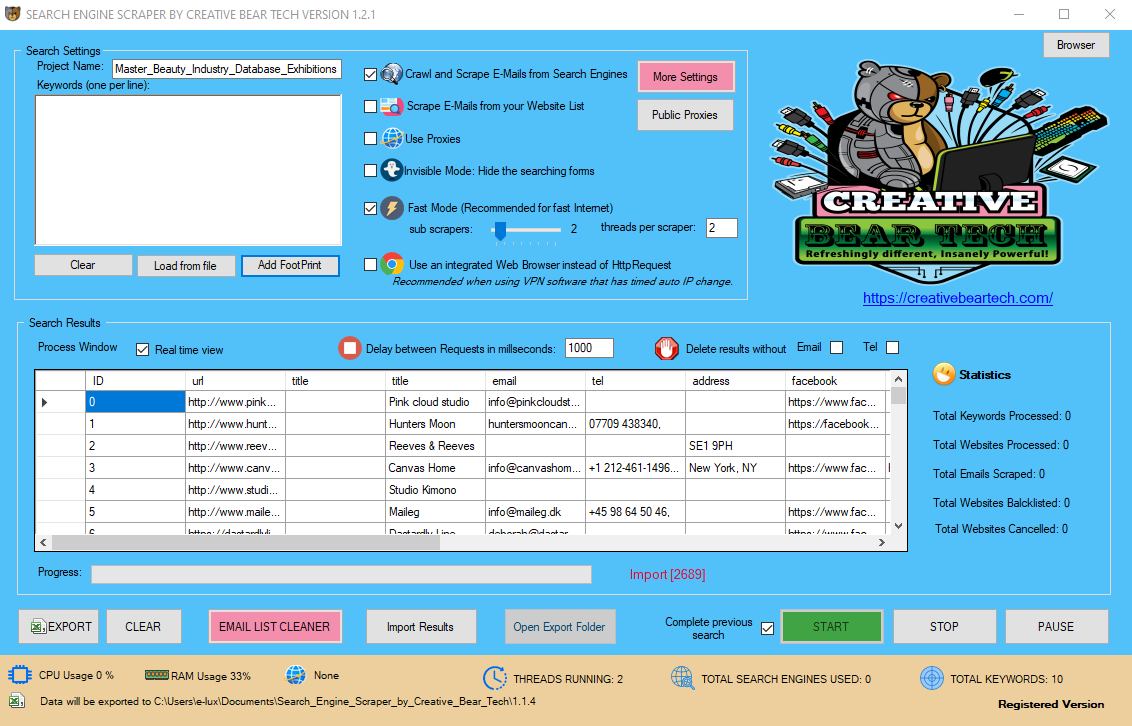
Inside the main GUI, you will need to select "scrape e-mails from your website list". You can use proxies but these are not essential. You can run the scraper in visible or "invisible mode" which will hide the windows. You can enable multi-threading by running the website scraping software in "fast mode". If you are using a VPN such as Nord VPN or HMA VPN PRO, you will need to check "use an integrated browser instead of http request". However, we do not recommend using a VPN because your Facebook account will get banned.
Next, you can enable or disable "real time view" at any time. The real time view will allow you to view the results in real time but this option will consume more computer processing power. We recommend keeping the delay between requests at their default of 1000 milliseconds. You can choose to delete results without email or telephone number.
If your website scraping tool crashes, your computer shuts down or it closes unexpectedly, you should check "complete previous search" next to the start button. The website scraper will load your settings and pick up where the website scraping software left off. You can also close your website scraper if you are shutting down your computer and open it up later and run it from the last position.
E-Mail List Cleaner
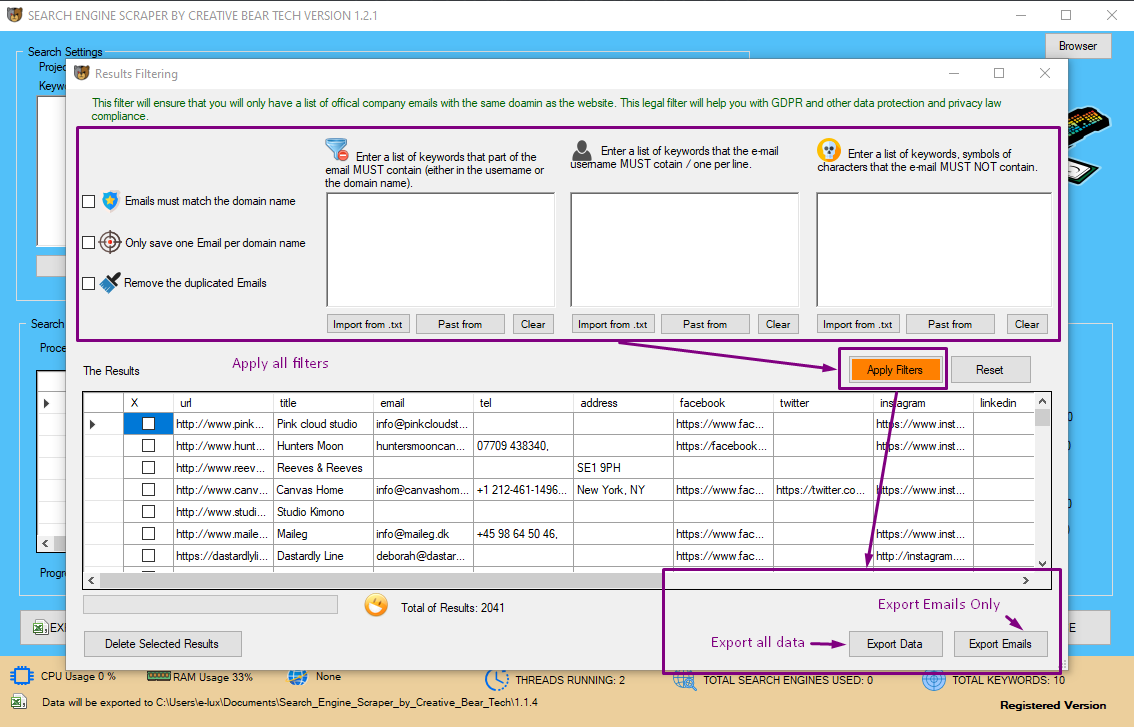
Once you have finished extracting data from your websites, you can open the email list cleaner where you will be able to remove emails that contain or do not contain certain keywords. You will also be able to remove emails that do not match the domain name (good for GDPR compliance) and also save only a specific number of emails from a single website. You can then export the entire data set in Excel CSV file by clicking on "Export Data" in the bottom right hand side corner and you can export only emails by clicking on "Export Emails" in CSV Excel file.