How to Configure Main Website Scraper and E-Mail Extractor Options
How to Configure Main Website Scraper and E-Mail Extractor Options
You should look at the main GUI screen of the website scraper. You will see a number of options. Below, we will give you a walk through of these option and explain what they represent.
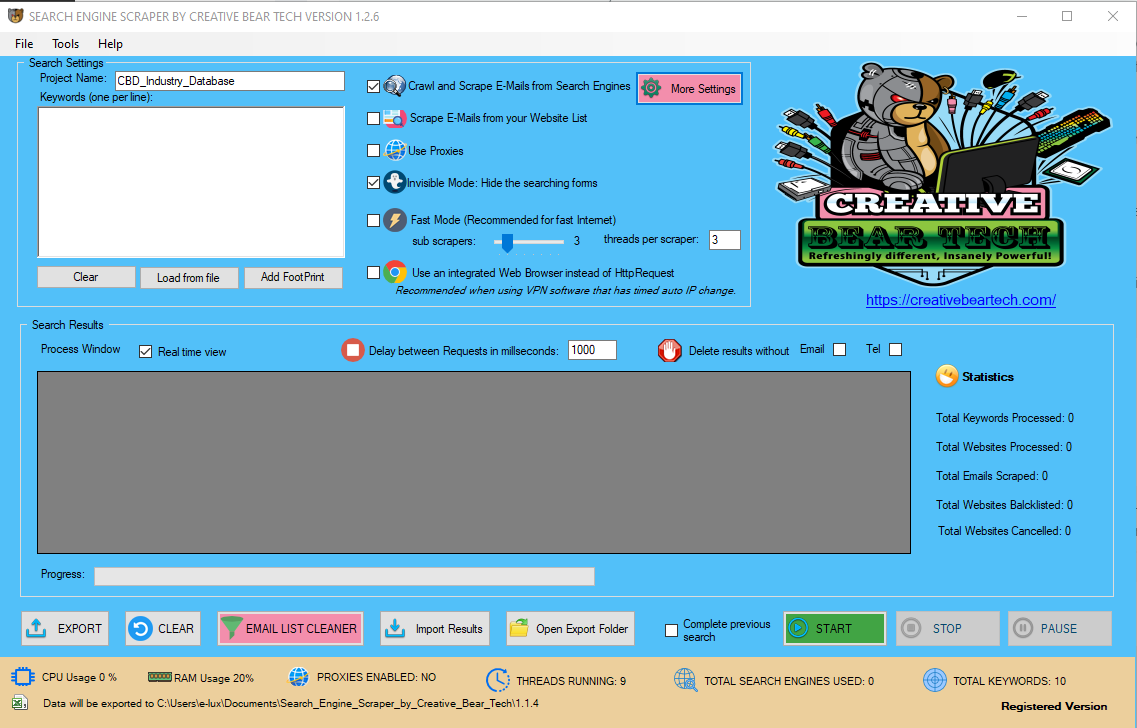
"Project Name" - this should be the name that represents your project. Please note: this exact project name will be used to create project folder and scraped results file. Make sure it is somethign meaningful. For example, CBD Industry Database or Vape Shop Database.
"Keywords" - unless you are scraping your own list of websites, you will need to enter your keywords here (one per line). You can also use the footprint option to generate your own keywords.
"Crawl and Scrape E-Mails from Search Engines" - Select this option only if you are NOT planning of scraping your own website list (i.e. you are planning to scrape Google, Bing, Google Maps, Yellow Pages, etc).
"Scrape E-Mail from your Website List" - select this option only if you are planning of scraping your own website list.
"Use Proxies" - you can use proxies. This is recommended if you are planning to use many threads and are planning of scraping Google, Google Maps, Yellow Pages, etc.
"Invisible Mode: Hire the searching forms" - this option will hide the browsers in which the scraping is happening.
"Fast Mode" - the website scraper will run on multiple threads. Be reasonable with the threads and make sure that your computer can handle the threads. Do some testing beforehand.
"Use an Integrated Web Browser Instead of HTTP request" - you should only ever enable this option if you are using a VPN software with timed out IP change. Generally, we do not recommend this option as it will interfere with Facebook account details and as you now know, Facebook is integral for ensuring complete results.
"Real time view" - you can view the results in real time. By disabling this option, you will save some processing power.
"Delay between Requests in milliseconds" - it is recommended to keep this at 1000.
"Delete results without email tel" - you can choose to delete results that do not have an email address or a telephone number.
"Complete previous search" - this is a very important feature. If your search engine scraper crashes for any reason or if you turn it off, you can always resume your previous search. If you are running the task manager, it will automatically restart the software and resume your previous search. This is recommended if you are running your software on an unattended computer or a Windows VPS.
"Import" - you can import your previous results and scrape additional data on top of them. This is helpful for building up your database instead of starting from scratch. All duplicates will be removed.
At the bottom of the data extractor, you will see the CPU usage, RAM usage, proxies status, threads, total keywords, total search engines, export folder.
Inside the help section, you can check for an update and submit a bug or a problem that you are experiencing directly to our team.